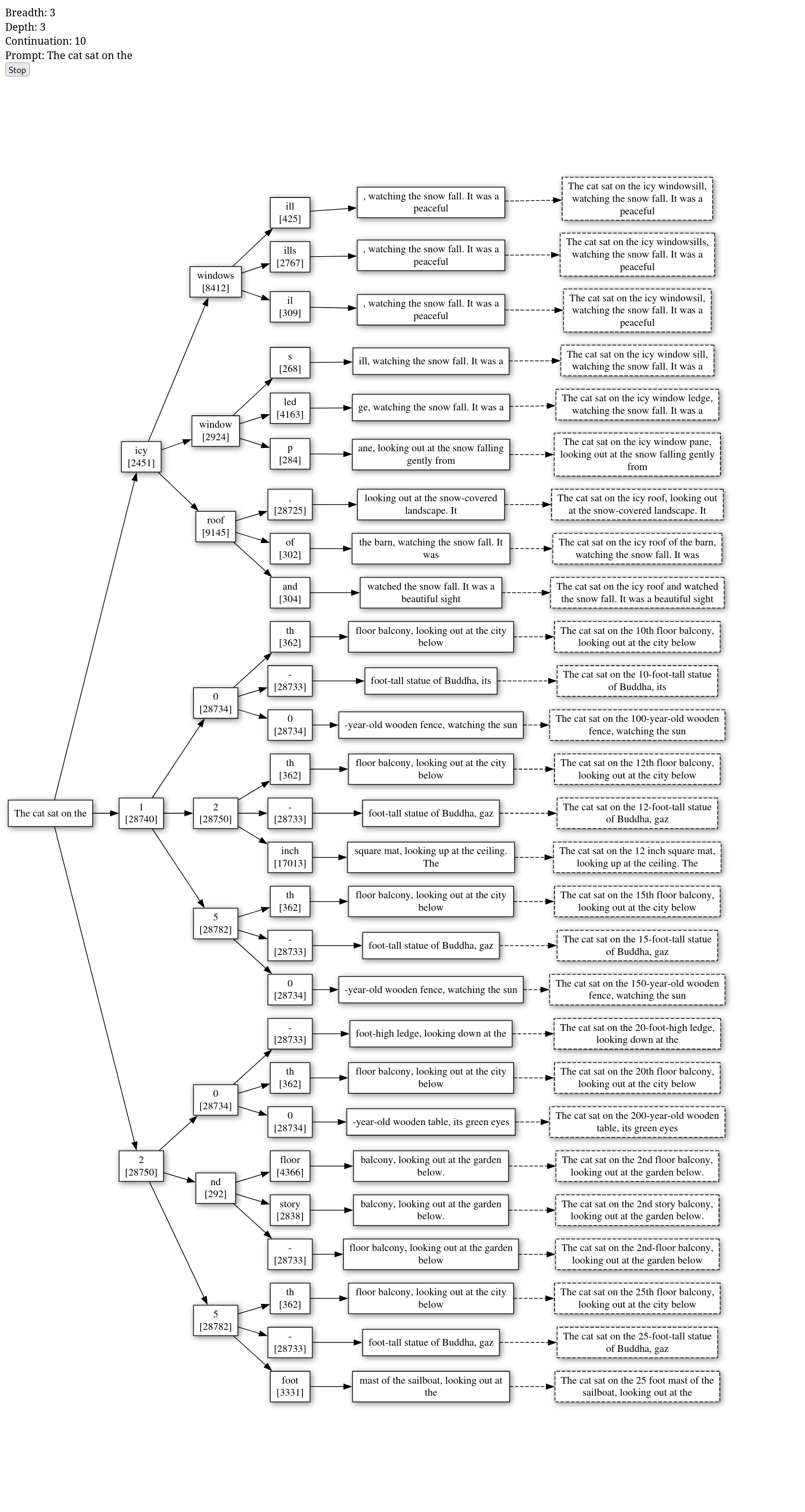
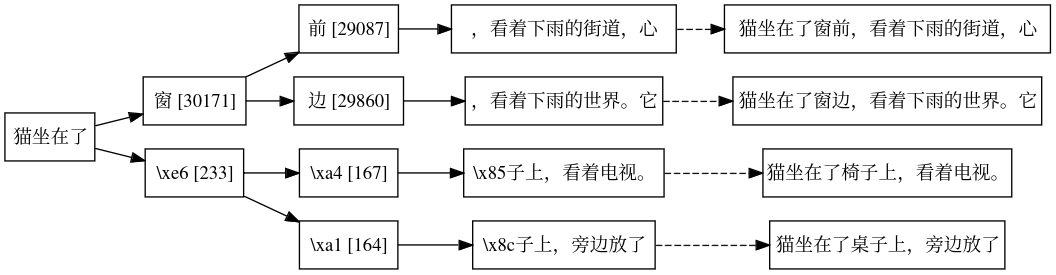
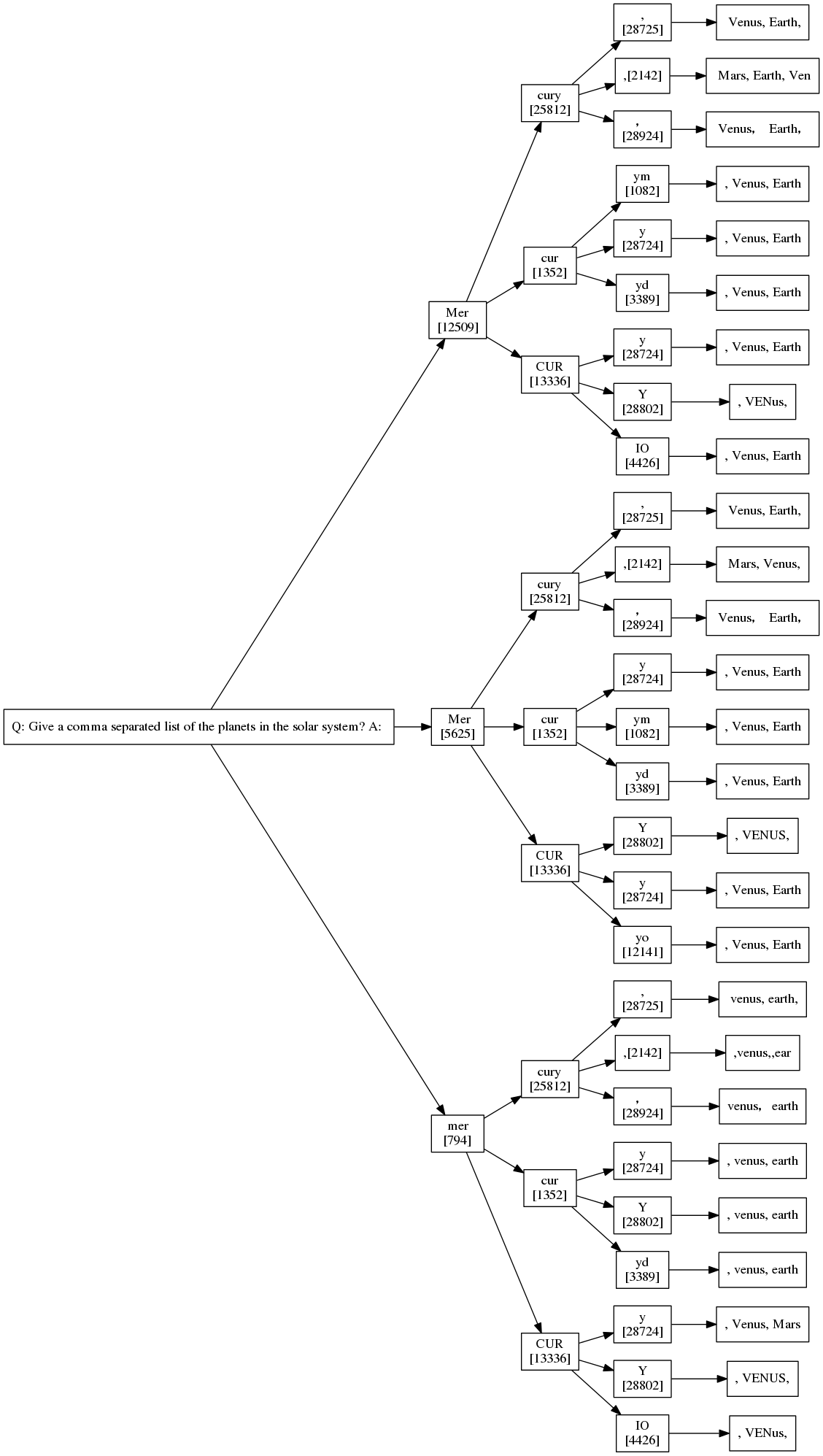
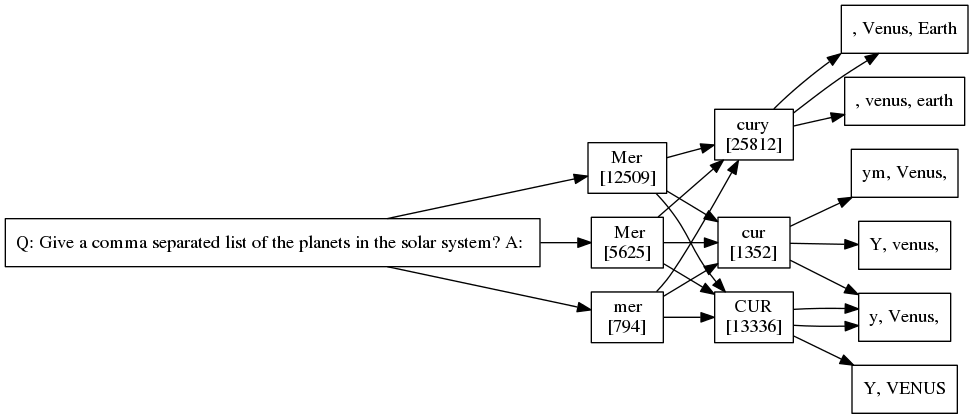
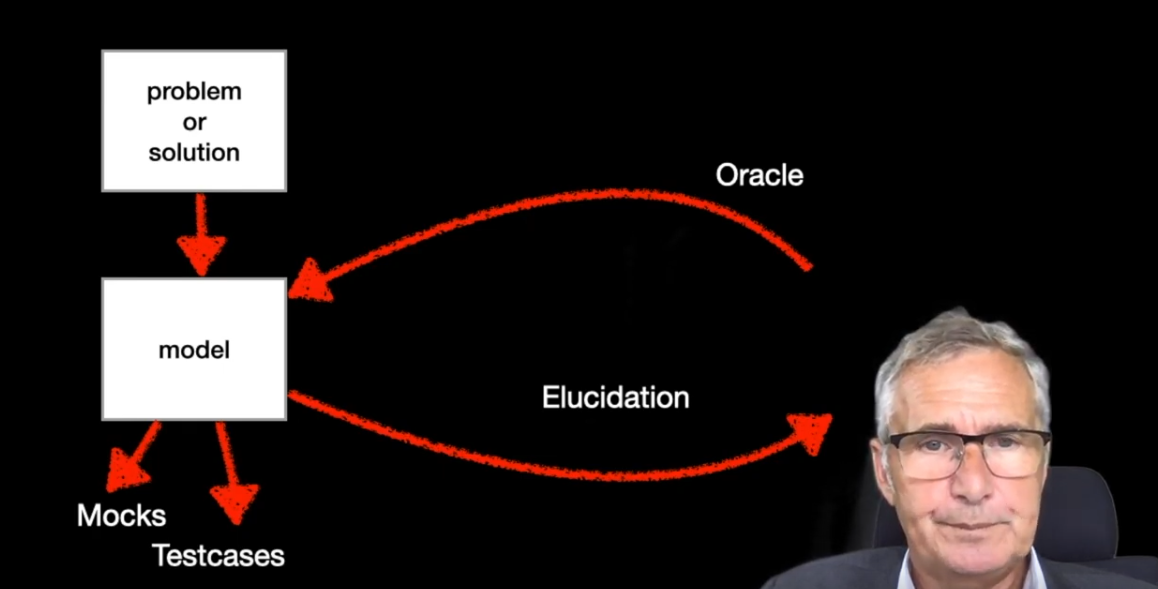
As both a learning exercise and a fun use of Bracketology, I built a web app to help you pick out a great white elephant gift! I did it initially with Clojure, ClojureScript, Reagent, Figwheel. I've now re-built it with Ruby, Opal, React.rb, and helped build the new opal-hot-reloader!